How to Scrape Stack Overflow Questions and Accepted Answers with Python (By Tag)
Stack Overflow is an unusually good scraping target for learning real-world HTML parsing because:
- the site is mostly server-rendered
- question pages have clear semantic structure
- pagination is explicit
- “accepted answer” is a concrete concept you can extract
In this guide we’ll write a scraper that:
- crawls a tag page (e.g.
python,node.js,selenium) - collects question URLs + basic metadata
- visits each question page and extracts:
- title, asked date, score
- accepted answer (if present)
- optionally a few top answers
- exports structured JSON you can use for search, datasets, or fine-tuning
We’ll also include a screenshot of the tag listing page so you can sanity-check your selectors.
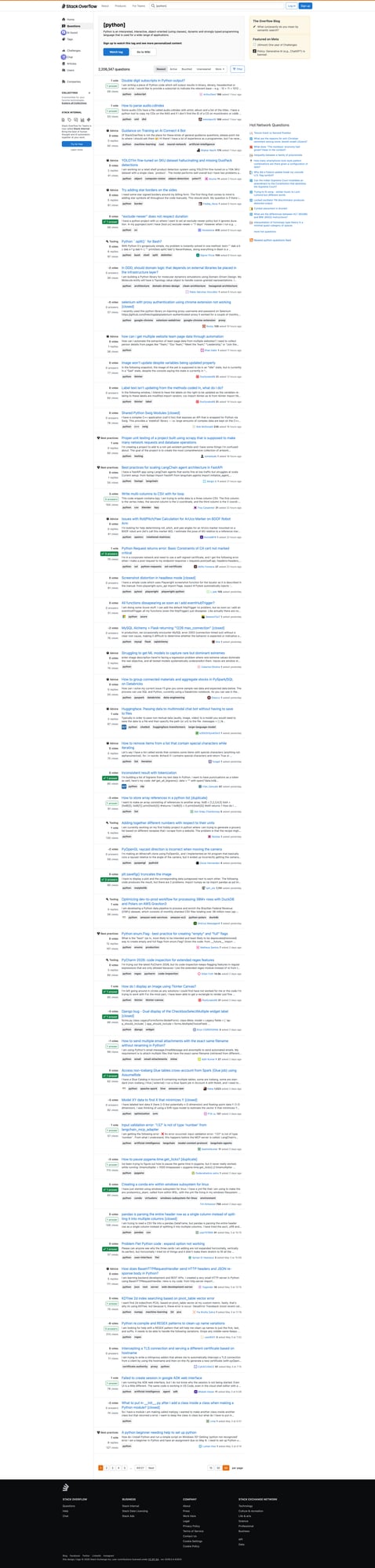
Stack Overflow is readable at small volumes, but when you crawl many tags + question pages, the failure rate climbs. ProxiesAPI helps keep your fetch layer stable via proxy rotation + reputation management.
What we’re scraping (URLs and structure)
Stack Overflow URLs we’ll use:
- tag listing:
https://stackoverflow.com/questions/tagged/python?tab=Newest&page=1&pagesize=50
- question detail:
https://stackoverflow.com/questions/QUESTION_ID/...
On a tag page, each question appears as a summary card.
On a question detail page, the post container includes:
- the question title
- the question body
- a list of answers
- an “accepted answer” indicator
Setup
python -m venv .venv
source .venv/bin/activate
pip install requests beautifulsoup4 lxml tenacity
Step 1: A fetch layer that won’t collapse (timeouts + retries)
import random
import time
import requests
from tenacity import retry, stop_after_attempt, wait_exponential
BASE = "https://stackoverflow.com"
TIMEOUT = (10, 30)
HEADERS = {
"User-Agent": (
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) "
"AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/124.0.0.0 Safari/537.36"
),
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
"Accept-Language": "en-US,en;q=0.9",
}
session = requests.Session()
def sleep_jitter(min_s=0.4, max_s=1.2):
time.sleep(random.uniform(min_s, max_s))
@retry(stop=stop_after_attempt(5), wait=wait_exponential(multiplier=1, min=1, max=20))
def fetch(url: str) -> str:
r = session.get(url, headers=HEADERS, timeout=TIMEOUT)
r.raise_for_status()
text = r.text
# basic block detection (imperfect)
if "captcha" in text.lower() and "stack overflow" in text.lower():
raise RuntimeError("Possible captcha page")
if len(text) < 20_000:
raise RuntimeError(f"Small HTML ({len(text)} bytes) — maybe an interstitial")
return text
ProxiesAPI integration point
If you need to scale the crawl, route through ProxiesAPI by adding proxies=...:
PROXIES = {
"http": "http://YOUR_PROXIESAPI_PROXY",
"https": "http://YOUR_PROXIESAPI_PROXY",
}
r = session.get(url, headers=HEADERS, proxies=PROXIES, timeout=TIMEOUT)
Keep credentials in environment variables.
Step 2: Crawl a tag page and extract question cards
We’ll extract:
- question URL
- question title
- vote count
- answer count
- view count
- asked date (when available in listing)
import re
from bs4 import BeautifulSoup
def abs_url(href: str) -> str:
if href.startswith("http"):
return href
return f"{BASE}{href}"
def parse_int(text: str) -> int | None:
if not text:
return None
text = text.replace(",", "").strip()
m = re.search(r"(\d+)", text)
return int(m.group(1)) if m else None
def parse_tag_page(html: str) -> list[dict]:
soup = BeautifulSoup(html, "lxml")
# question summaries are inside divs with question links
cards = soup.select("div.s-post-summary")
out = []
for c in cards:
a = c.select_one("a.s-link")
if not a:
continue
href = a.get("href")
url = abs_url(href) if href else None
title = a.get_text(" ", strip=True)
# Stats blocks
votes = parse_int((c.select_one("span.s-post-summary--stats-item-number") or {}).get_text(" ", strip=True) if c.select_one("span.s-post-summary--stats-item-number") else "")
answers_el = c.select_one("div.s-post-summary--stats-item:nth-of-type(2) span.s-post-summary--stats-item-number")
answers = parse_int(answers_el.get_text(" ", strip=True) if answers_el else "")
views_el = c.select_one("div.s-post-summary--stats-item:nth-of-type(3) span.s-post-summary--stats-item-number")
views = parse_int(views_el.get_text(" ", strip=True) if views_el else "")
out.append({
"url": url,
"title": title,
"votes": votes,
"answers": answers,
"views": views,
})
return out
Note: Stack Overflow’s listing HTML changes occasionally. If div.s-post-summary stops matching, open the page source and adjust the selector.
Step 3: Parse a question page and extract the accepted answer
On the question page, we’ll extract:
- question title
- question score
- asked timestamp
- accepted answer (HTML → text)
from bs4 import BeautifulSoup
def extract_post_text(post) -> str:
# Keep line breaks for code blocks and paragraphs
return post.get_text("\n", strip=True)
def parse_question_page(html: str) -> dict:
soup = BeautifulSoup(html, "lxml")
title_el = soup.select_one("h1 a.question-hyperlink") or soup.select_one("h1")
title = title_el.get_text(" ", strip=True) if title_el else None
# question score
q_score_el = soup.select_one("div.question div.js-vote-count")
q_score = int(q_score_el.get("data-value")) if q_score_el and q_score_el.get("data-value") else None
# asked date
asked_time = None
asked_el = soup.select_one("time[itemprop='dateCreated']") or soup.select_one("time")
if asked_el:
asked_time = asked_el.get("datetime") or asked_el.get_text(" ", strip=True)
# question body
q_body_el = soup.select_one("div.question div.s-prose")
question_text = extract_post_text(q_body_el) if q_body_el else None
accepted_text = None
# accepted answer: look for an answer with accepted indicator
# Stack Overflow marks accepted answer via classes/attributes that can vary.
accepted = soup.select_one("div.answer.accepted-answer")
if not accepted:
# fallback: an answer that contains the green check icon area
for ans in soup.select("div.answer"):
if ans.select_one("div.js-accepted-answer-indicator") or ans.select_one("span.js-accepted-answer-indicator"):
accepted = ans
break
if accepted:
a_body_el = accepted.select_one("div.s-prose")
accepted_text = extract_post_text(a_body_el) if a_body_el else None
return {
"title": title,
"asked": asked_time,
"question_score": q_score,
"question_text": question_text,
"accepted_answer_text": accepted_text,
}
Step 4: Crawl N pages, dedupe, and export JSON
import json
def crawl_tag(tag: str, pages: int = 2, page_size: int = 50) -> list[dict]:
seen = set()
questions = []
for p in range(1, pages + 1):
url = f"{BASE}/questions/tagged/{tag}?tab=Newest&page={p}&pagesize={page_size}"
html = fetch(url)
sleep_jitter()
batch = parse_tag_page(html)
for q in batch:
if not q.get("url") or q["url"] in seen:
continue
seen.add(q["url"])
questions.append(q)
print("page", p, "batch", len(batch), "total", len(questions))
return questions
def enrich_questions(questions: list[dict], limit: int = 10) -> list[dict]:
out = []
for q in questions[:limit]:
html = fetch(q["url"])
sleep_jitter(0.6, 1.4)
details = parse_question_page(html)
out.append({**q, **details})
print("enriched", len(out), q.get("title"))
return out
def main():
tag = "python" # change me
questions = crawl_tag(tag, pages=3, page_size=50)
enriched = enrich_questions(questions, limit=20)
with open(f"so_{tag}_questions.json", "w", encoding="utf-8") as f:
json.dump(enriched, f, ensure_ascii=False, indent=2)
print("wrote", f"so_{tag}_questions.json", len(enriched))
if __name__ == "__main__":
main()
QA checklist
- Tag page selector finds ~50 cards (pagesize)
- Question URLs look correct and open in browser
-
parse_question_page()returns a title + question body - Accepted answer text is present for questions that have one
Practical tips (don’t get blocked)
- Keep
pagessmall and add jitter. - Cache fetched HTML on disk for development.
- When scaling, use ProxiesAPI + slower rates.
- Respect robots.txt and the site’s terms.
Next upgrades
- store in SQLite and update incrementally
- add
If-Modified-Since/ ETags if available - detect “accepted answer” more robustly by inspecting current DOM
- add a Playwright fallback for edge cases
Stack Overflow is readable at small volumes, but when you crawl many tags + question pages, the failure rate climbs. ProxiesAPI helps keep your fetch layer stable via proxy rotation + reputation management.